

What is OPA and why should you care?
Picture this: you’re managing a sprawling cloud infrastructure with dozens of teams spinning up resources left and right. How do you ensure everyone follows security best practices without becoming the bottleneck that slows everything down? Enter Open Policy Agent (OPA) – your new best friend in the world of policy-as-code.
If you’ve ever found yourself drowning in a sea of manual compliance checks or watching helplessly as someone accidentally exposes a database to the internet (we’ve all been there), this guide is for you. We’re going to dive deep into building robust cloud infrastructure policies with OPA, and I promise to keep it practical and pain-free.
Open Policy Agent is like having a bouncer at every door of your infrastructure – but instead of checking IDs, it’s validating whether actions comply with your organization’s policies. It’s a general-purpose policy engine that decouples policy decision-making from policy enforcement, and here’s the kicker: it does this using a declarative language called Rego.
Think of OPA as your infrastructure’s rulebook that actually gets read and followed. Unlike those dusty compliance documents sitting in a SharePoint somewhere, OPA policies are living, breathing code that actively prevents bad things from happening. Whether you’re working with Kubernetes, Terraform, or cloud APIs, OPA can step in and say, “Hold up, that’s not allowed!”
Getting started with OPA basics
Before we jump into the deep end, let’s get comfortable with the shallow waters. OPA works on a simple principle: you give it some data (like a Terraform plan or a Kubernetes manifest), it evaluates it against your policies, and then returns a decision. It’s like asking, “Can I do this?” and getting a clear yes or no answer, along with the reasons why.
The beauty of OPA lies in its flexibility. You can integrate it at multiple points in your infrastructure lifecycle – during development, in your CI/CD pipeline, or even at runtime. It’s not prescriptive about where it fits; instead, it adapts to your existing workflows like water filling a container.
Here’s what makes OPA particularly powerful for cloud infrastructure: it understands JSON and YAML natively, which means it can work with pretty much any configuration format you throw at it. Terraform plans? Check. Kubernetes manifests? Absolutely. AWS CloudFormation templates? You bet.
Writing your first infrastructure policy with Rego
Now, let’s roll up our sleeves and write some actual policies. Rego might look a bit alien at first (I certainly did a double-take when I first saw it), but once you get the hang of it, it’s surprisingly intuitive. Think of Rego as asking questions about your data and building up answers piece by piece.
Let’s start with a simple but practical example. Say you want to ensure that all S3 buckets in your AWS infrastructure are encrypted. Here’s how you’d write that policy:
package aws.s3.encryption
default allow = false
allow if {
input.resource_type == "aws_s3_bucket"
input.encryption.enabled == true
}
deny[msg] if {
input.resource_type == "aws_s3_bucket"
not input.encryption.enabled
msg := sprintf("S3 bucket %s must have encryption enabled", [input.name])
}See what we did there? We’re basically saying, “By default, don’t allow anything. But if it’s an S3 bucket AND encryption is enabled, then it’s okay.” Simple, right? The deny rule even provides a helpful message explaining what went wrong.
Implementing policy governance for Terraform
Terraform is where OPA really shines in the infrastructure-as-code world. Instead of discovering policy violations after resources are created (and scrambling to fix them), you can catch issues before they even make it to your cloud provider. It’s like having spell-check for your infrastructure code.
Here’s where things get interesting. You can integrate OPA with Terraform in multiple ways, but one of the most effective approaches is using it with Terraform plan outputs. After running terraform plan, you can export the plan as JSON and feed it to OPA for evaluation. This gives you a complete picture of what’s about to change and whether it complies with your policies.
Let me share a more complex example that checks for proper tagging standards:
package brainboard
required_tags := ["Environment", "Owner", "CostCenter", "Project"]
deny[msg] if {
resource := input.planned_values.root_module.resources[_]
resource.type == "aws_instance"
missing_tags := required_tags[_]
not resource.values.tags[missing_tags]
msg := sprintf("EC2 instance %s is missing required tag: %s", [resource.address, missing_tags])
}
deny[msg] if {
resource := input.planned_values.root_module.resources[_]
resource.type == "aws_instance"
resource.values.tags.Environment
not regex.match("^(dev|staging|prod)$", resource.values.tags.Environment)
msg := sprintf("EC2 instance %s has invalid Environment tag value", [resource.address])
}You can then run OPA with “brainboard/deny”, to check against the deny rule.
This policy ensures that all EC2 instances have the required tags and that the Environment tag contains only approved values. It’s like having an automated compliance officer reviewing every change before it happens.
Building comprehensive security policies
Security policies are where OPA transforms from a nice-to-have to an absolute necessity. You’re not just checking boxes anymore; you’re actively preventing security misconfigurations that could lead to data breaches or compliance violations.
Let’s tackle a common security concern: ensuring that security groups don’t allow unrestricted access from the internet. Here’s a policy that would catch this:
package aws.security_groups
deny[msg] if {
resource := input.planned_values.root_module.resources[_]
resource.type == "aws_security_group_rule"
resource.values.type == "ingress"
resource.values.cidr_blocks[_] == "0.0.0.0/0"
resource.values.from_port == 22
msg := sprintf("Security group rule %s allows SSH access from the entire internet", [resource.address])
}
deny[msg] if {
resource := input.planned_values.root_module.resources[_]
resource.type == "aws_security_group_rule"
resource.values.type == "ingress"
resource.values.cidr_blocks[_] == "0.0.0.0/0"
resource.values.from_port <= 3389
resource.values.to_port >= 3389
msg := sprintf("Security group rule %s allows RDP access from the entire internet", [resource.address])
}These policies catch two of the most common security mistakes: leaving SSH and RDP ports open to the world. It’s like having a security expert review every single change, except this expert never gets tired, never misses anything, and works at the speed of light.
Integrating OPA into your CI/CD pipeline
Now here’s where the rubber meets the road. Having policies is great, but if they’re not enforced automatically, they’re just suggestions. Integrating OPA into your CI/CD pipeline turns those suggestions into iron-clad rules that can’t be bypassed.
The integration typically happens at multiple stages. During the pull request phase, OPA can evaluate proposed changes and provide feedback directly in the PR comments. If policies are violated, the PR can be blocked from merging. It’s like having a code review that never forgets to check the important stuff.
Here’s a practical example of how you might integrate OPA into Brainboard:
-
Configure:
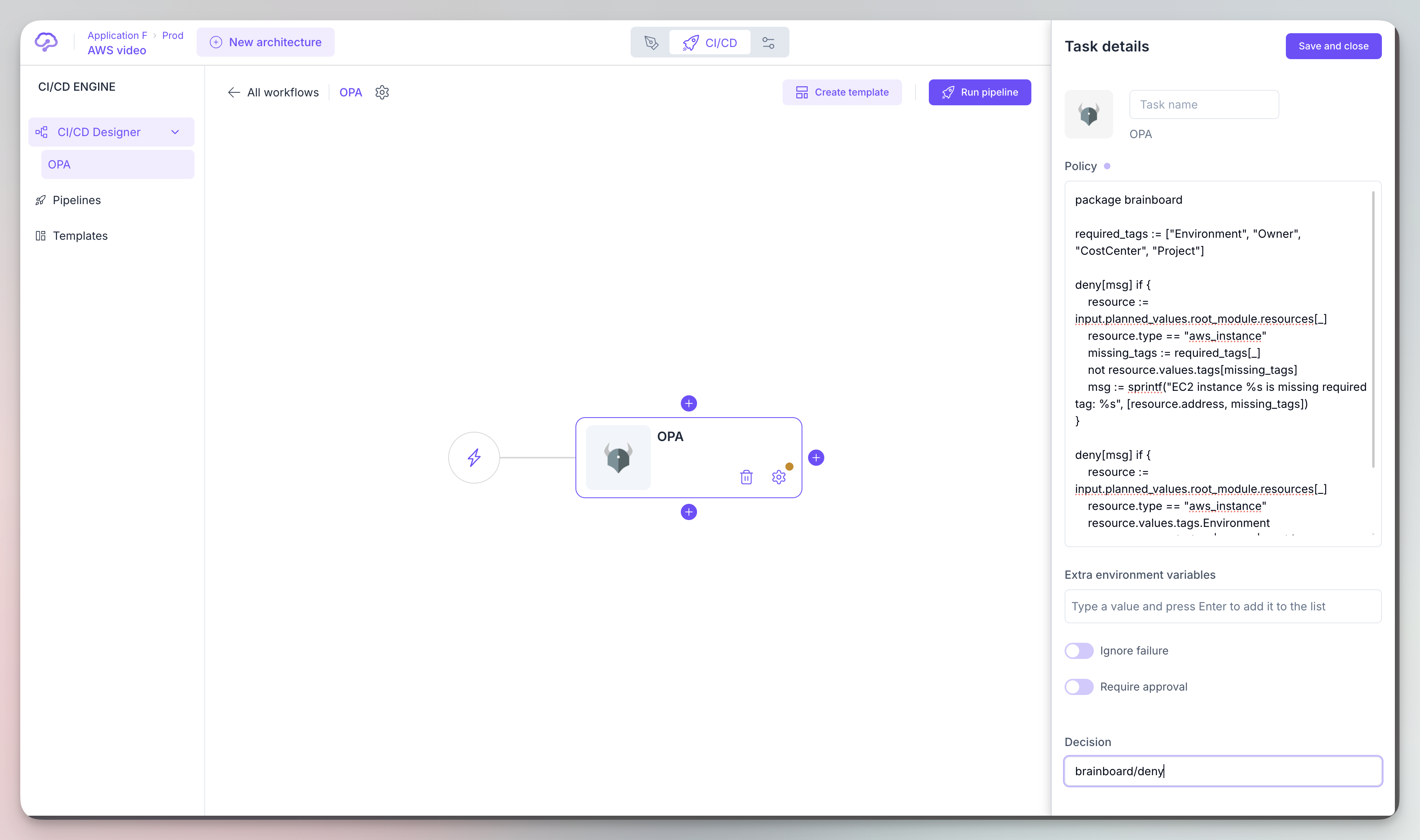
Brainboard OPA configuration -
Evaluate:
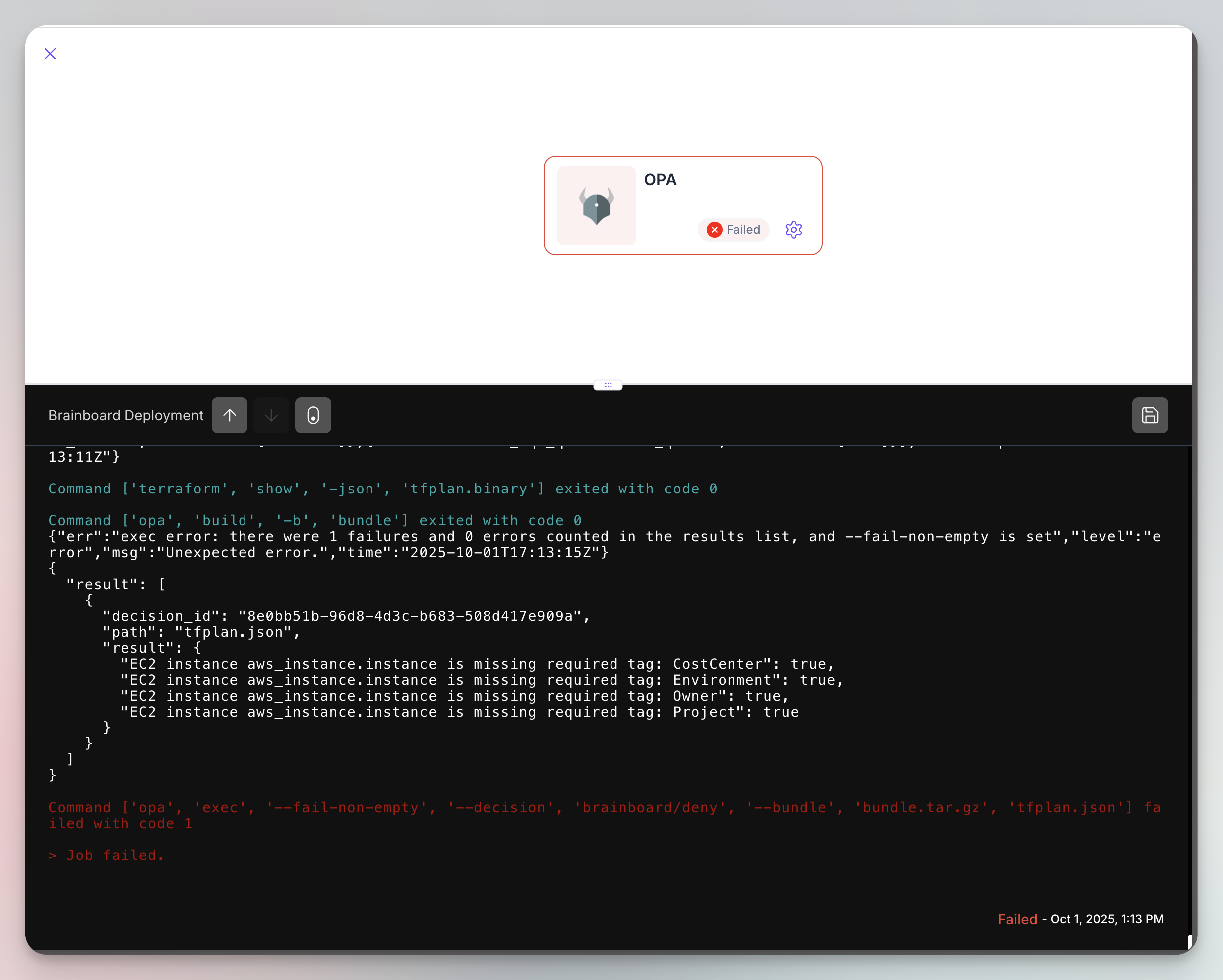
Brainboard OPA output
This workflow ensures that no infrastructure changes can make it to production without passing your policy checks. It’s automated governance at its finest.
Managing policy exceptions and overrides
Let’s be real for a moment – no matter how well-crafted your policies are, there will always be legitimate exceptions. Maybe you need to temporarily open a port for debugging, or perhaps there’s a legacy system that can’t comply with new standards yet. OPA handles this gracefully through policy exceptions.
You can build exception mechanisms directly into your policies. Here’s an example that allows certain resources to bypass policies if they’re properly documented:
package exceptions
import future.keywords.in
# Define exceptions with expiration dates
exceptions := {
"aws_instance.legacy_app": {
"reason": "Legacy application - migration planned for Q3 2024",
"expires": "2024-09-30",
"approved_by": "security-team"
}
}
# Check if a resource has a valid exception
has_valid_exception(resource_address) {
exception := exceptions[resource_address]
today := time.now_ns() / 1000000000
expiry := time.parse_rfc3339_ns(exception.expires) / 1000000000
today < expiry
}
# Modify your deny rules to check for exceptions
deny[msg] if {
resource := input.planned_values.root_module.resources[_]
# Your normal validation logic here
not has_valid_exception(resource.address)
msg := sprintf("Resource %s violates policy and has no valid exception", [resource.address])
}This approach maintains the integrity of your policies while providing a documented, time-limited escape hatch for special cases. It’s like having a hall pass system that automatically expires.
Testing and debugging your policies
Writing policies without testing them is like writing code without running it – you’re flying blind. OPA provides excellent testing capabilities that let you validate your policies before they go live. Think of it as unit testing for your governance rules.
Here’s how you can write tests for your policies:
package aws.s3.encryption_test
import data.aws.s3.encryption
test_encrypted_bucket_allowed {
encryption.allow with input as {
"resource_type": "aws_s3_bucket",
"encryption": {"enabled": true}
}
}
test_unencrypted_bucket_denied {
not encryption.allow with input as {
"resource_type": "aws_s3_bucket",
"encryption": {"enabled": false}
}
}
test_deny_message_correct {
expected_msg := "S3 bucket my-bucket must have encryption enabled"
expected_msg in encryption.deny with input as {
"resource_type": "aws_s3_bucket",
"name": "my-bucket",
"encryption": {"enabled": false}
}
}Run these tests with opa test and you’ll know immediately if your policies work as expected. It’s like having a safety net that catches bugs before they can cause problems in production.
Here is an OPA playground that helps you test your policies before pushing them to prod.
Best practices for scaling OPA policies
As your infrastructure grows, so will your policy requirements. What starts as a handful of simple rules can quickly balloon into hundreds of complex policies. Without proper organization, you’ll end up with a tangled mess that nobody wants to maintain.
Here are some battle-tested practices for keeping your policies manageable:
First, organize your policies by domain. Don’t dump everything into one massive file. Instead, structure them like this:
policies/
├── aws/
│ ├── ec2/
│ │ ├── instances.rego
│ │ └── security_groups.rego
│ ├── s3/
│ │ └── buckets.rego
│ └── rds/
│ └── databases.rego
├── kubernetes/
│ ├── pods.rego
│ └── services.rego
└── common/
└── tags.regoSecond, use policy libraries for common patterns. If you find yourself writing the same validation logic repeatedly, extract it into a reusable function. It’s the DRY principle applied to policy-as-code.
Third, version your policies alongside your infrastructure code. Policies are code, and they should be treated with the same rigor. Use Git, create pull requests, and maintain a changelog. Your future self will thank you when trying to understand why a particular policy was added.
Monitoring and observability for policy decisions
Once your policies are in production, you need visibility into what they’re doing. Are they blocking legitimate changes? Are certain policies triggering more often than expected? Without monitoring, you’re operating in the dark.
OPA provides decision logs that capture every policy evaluation. You can ship these logs to your favorite monitoring platform and create dashboards that show policy effectiveness. Here’s what a basic monitoring setup might track:
- Total policy evaluations per hour
- Denial rate by policy package
- Most frequently violated policies
- Policy evaluation latency
- Exception usage patterns
This data is gold for understanding how your policies impact your organization. Maybe you’ll discover that a particular policy is too strict and causing friction, or perhaps you’ll find gaps where additional policies are needed.
Conclusion
Building cloud infrastructure policies with OPA isn’t just about compliance or security – it’s about codifying your organization’s best practices and making them enforceable at scale. You’re essentially teaching your infrastructure to manage itself according to your rules.
We’ve covered a lot of ground here, from writing your first Rego policy to building a comprehensive policy framework that scales with your organization. The key takeaway? Start small, test everything, and gradually expand your policy coverage as you gain confidence.
Remember, perfect is the enemy of good when it comes to policy implementation. It’s better to have basic policies running today than to spend months designing the perfect system that never ships. Your policies will evolve as your infrastructure and requirements change, and that’s exactly how it should be.
FAQs
How does OPA compare to cloud-native policy tools like AWS Config or Azure Policy?
While cloud-native tools are excellent for their specific platforms, OPA provides a unified policy engine that works across multiple clouds and technologies. You write policies once in Rego and apply them everywhere – from Terraform plans to Kubernetes manifests to API calls. It’s like having a universal translator for infrastructure policies rather than learning a different language for each platform.
an OPA policies impact infrastructure deployment performance?
OPA is designed to be lightning-fast, with most policy evaluations completing in milliseconds. However, complex policies with extensive data processing can add latency. The key is to run policy checks asynchronously in your CI/CD pipeline rather than inline during deployments. This way, you get the benefits of policy enforcement without impacting deployment speed.
What’s the learning curve for Rego, and how can teams get up to speed quickly?
Rego does have a unique syntax that takes some getting used to – expect about a week to feel comfortable and a month to feel proficient. The best approach is to start with simple policies and gradually increase complexity. The OPA Playground (play.openpolicyagent.org) is invaluable for experimenting, and there’s a growing library of example policies you can adapt rather than writing from scratch.
How do you handle policy updates without breaking existing infrastructure?
Policy updates should follow the same deployment practices as application code. Use a staging environment to test new policies against real infrastructure plans, implement gradual rollouts, and always have a rollback plan. Consider using policy versioning where different environments can run different policy versions during the transition period.
Can OPA integrate with existing SIEM or compliance tools?
Absolutely! OPA’s decision logs can be exported in JSON format and ingested by virtually any SIEM platform. You can create alerts for policy violations, generate compliance reports, and even trigger automated remediation workflows. Many organizations pipe OPA logs into tools like Splunk, ELK stack, or Datadog for centralized monitoring and compliance reporting.